TomBot2000: automatically finding related posts using LLMs
How I used LLM embeddings to find related posts for my statically-generated blog and then used GPT4 to explain why they're similar.

If you're just interested in the code for this project, you can find it on GitHub: github.com/tomhazledine/related-posts. Try it out and let me know what you think 👍
I've been having a lot of fun lately with embeddings. They are a somewhat-overlooked sideshow to the current GPT/LLM/AI circus, but in my view they are even more interesting than the headline-grabbing chat apps. And unlike the the chat interfaces, embeddings are a way to make LLMs actually useful without any of the worries about "hallucination" or just-plain-wrong content.
A large part of what I've been using embeddings for is "natural language search" which (at the simplest level) involves defining how similar two bits of text are. Give the robots two different pieces of content and they then decide how similar the "meanings" of the two pieces are on a scale of 0.0 to 1.0. This is great for search applications where it neatly sidesteps the need for complex algorithms and complicated matching engines (rendering a lot of my previous search work charmingly obsolete!), but it's also a neat solution to a problem that I've been halfheartedly grappling with for years: finding "related posts" for blog content.
Why do I care about related posts?
When I talk about "related posts", what I'm referring to is the section at the end of an article that points the reader to other, similar content. The promise being made to any reader that reaches the end of an article or post is: "If you liked reading that, then you'll probably be interested in this too".
Partly I want to make my sites more useful to people who visit them, but mostly I just want to keep readers on my site. I've been working on blog-style content sites for well over a decade-and-a-half at this point, and I'm keenly aware of how tough a challenge "audience retention" can be.
The default option of "next post" and "previous post" links (I default option I've often used myself) doesn't really provide much value. Only the most ardent completionists are going to work their way through a site from the very start to the very end. If you can surface related content instead, that's inevitably going to be more useful.
How have I tried and failed to generate related posts in the past?
Failed attempt #1: the manual approach
The "easiest" way to add related content to the bottom of a post is to do it manually. By which I mean picking a couple of posts that you have personally decided are related to the post you've just written. Then you type the links out at the end of the post's content yourself. You, the post's author, do the choosing. You find the links. You write the description. In many ways this is probably the best way to do it, but there are a few issues:
- You can only choose from content that already exists. This is because the related content you select is limited to the articles or posts you've already published, leaving no room for future publications to be included. In theory, you could revisit every post every time you add a new one and update the related links, but this quickly becomes impractical and time-consuming.
- The links you choose might break. Once you have hand-written a related post link, that link is locked in place. If the permalink for the related post changes (for example, if you update the title of the post or change the structure of your site) then you need to remember to come back and update the link (or at the very least setup a 303 redirect). Again, this is lots of work, and an almost certain recipe for "dead links" once your site reaches any kind of scale.
- It's a lot of work. Both issues 1. and 2. involve a lot of manual effort, but there's also the cognitive overhead of keeping all your posts' content in your head. Plus it takes a lot of time and brainpower to come up with the "relations" in the first place.
In short, choosing related posts is a process that cries out for automation.
Failed attempt #2: leaning on CMS features
One massive time saving that can be made is to define "related posts" in whatever CMS you're using. Back (way back!) when I used WordPress, it was relatively trivial to add a custom field to the edit screen that allowed me to select any existing post from a dropdown. With that mechanic in place it's possible to quickly select a "related" post (or several) whenever a new post is written.
This is still a slightly manual process because you still have to choose the relations, but it does avoid some of the pitfalls of an entirely manual process:
- By selecting a post from within the CMS rather than by pasting a URL string, the relation is dynamically linked to the post object (meaning if the title or permalink change, the "related" link inherits those changes).
- Because this approach uses the post object there are also more possibilities at the presentational level, as templates can access any part of the post (meaning the "related posts" section of the page can include post excerpts, thumbnail images, or any other content associated with the post).
Another potential enhancement is to fully automate the process by letting the CMS automatically select related posts for you. In WordPress land there are no doubt plenty of plugins that offer this functionality (but as with all WP plugins, proceed with caution. Here be dragons!). I've used a couple myself over the years, and they've been fine. As far as I can tell they use a combination of metadata matching (are these posts in the same category, for example?) and "traditional" search queries to compare posts (although how they build their queries I do not know - if I was building a plugin like this I'd probably use some combination of post-title and excerpt to get the best balance of accuracy and performance).
But static sites don't use a CMS...
The biggest caveat to this whole approach (and the reason I haven't used it in years) is that a static site doesn't have a CMS. And, in case you missed it, I'm a huge advocate of static sites and static site generators. Sure, some of you might be using a fancy headless CMS or whatever, but for me one of the main appeals of running a static site is that all my content is nothing more than a folder full of markdown files.
The one major downside to just using markdown files is that if you want any custom metadata (such as links to related posts) you have to write it in yourself. The format is a bit more structured than yolo-ing it in the main content flow as-per the fully manual approach (if you can call YAML structured #shotsFired), but still comes with all the same downsides.
So what are embeddings?
Embeddings power my 100%-automated related posts workflow. The general concept of "embeddings" is an offshoot of the Large Language Model (LLM) technology that makes tools like ChatGPT work. The basic idea is that you can take a piece of text (a blog post, for example) and turn it into a vector (an array of numbers). This vector is called an "embedding" and it represents the "meaning" of the text. It's a weird concept to get your head around at first, but you can learn more about embeddings in detail in Simon Willion's excellent explainer, "Embeddings: What they are and why they matter".
The way I think about it is like this: an embedding is a mathematical representation of the meaning of a chunk of content. And because the embedding is an array of numbers it can be treated as a set of coordinates. If the embedding was a simple one with only two numbers, you could plot it on a 2D graph and the the position of that point on the graph would represent the meaning of the text used to create the embedding. In essence, by using embeddings you're creating a "map" of the meaning of your content.
Of course it's more complex than that as the embeddings are actually a lot longer than two numbers, but the principle is the same. The longer the vector, the more dimensions you have to plot the point in. The more dimensions you have, the more accurate the representation of the meaning of the text. I've been using OpenAI's ada-002 model to create my embeddings, and the embeddings it creates are made up of 1536 numbers. To plot these vectors on a graph you'd need to (somehow) visualise a 1536-dimensional space. Like I said, it's a tricky concept to get your head around.
Using embeddings for "natural language search"
It is the "semantic mapping" aspect of embeddings that make them useful. If you have a set of embeddings created from different strings of text, their "position" in 1536-dimensional space represents their meaning. If they are close, then the meanings are similar. If they are far apart, then the meanings are different.
The practical application of this "closeness" is that you can measure how "close" multiple embeddings are and compare them against each other. If one of your strings happens to be a "search query", then tada: you've built a search engine! Rig up an input field to generate an embedding of whatever question the user asks, and then compare that embedding to the embeddings of all your content.
That simple search engine will work just fine with "normal" queries that you'd type into any old search box, but it would also work really well with natural language queries.
And the similarity is computationally "easy" to calculate, too. If you've already done the work to create the embeddings, then the similarity can be worked out with a function known as cosine similarity.
export const cosineSimilarity = (a, b) => {
const dotProduct = a.reduce((acc, cur, i) => acc + cur * b[i], 0);
const magnitudeA = Math.sqrt(a.reduce((acc, cur) => acc + cur ** 2, 0));
const magnitudeB = Math.sqrt(b.reduce((acc, cur) => acc + cur ** 2, 0));
const magnitudeProduct = magnitudeA * magnitudeB;
const similarity = dotProduct / magnitudeProduct;
return similarity;
};
There's a lot of (to my eyes) complicated maths going on in that cosineSimilarity function, but thankfully you don't need to understand exactly how it works to use it effectively. (Although of course you can just copy/paste that function into ChatGPT and get a pretty decent explanation).
Complex or not, calculating cosine similarity is a lot less work than creating a fully-fledged search algorithm, and the results will be of similar quality. In fact, I'd be willing to bet that the embedding-based search would win a head-to-head comparison most of the time.
There are some caveats to this, as how you've divided up the content before creating your embeddings will effect the results (did you embed every sentence, or every paragraph, or the whole article as a single embedding? Those choices will have consequences).
Handy fact: hallucination is not a problem when working with embeddings
Anyone who's used LLMs for any amount of time will have hit upon the biggest obstacle to using them for "proper work": LLMs hallucinate. Yep, they just make stuff up all the time, giving you "facts" that sound plausible but may or may not actually be true. This is an issue with all chat-based LLM interactions where the LLM is generating text.
The beauty of using LLM embeddings is that at no point is any text being generated. An LLM generates an embedding of text that we explicitly gave it. The "AI magic" is in how it turns the meaning of the text into a list of numbers. We don't need it to generate any text for us, so there's no scope for making stuff up.
Can embeddings be used to calculate relations between our content?
In short: yes, yes it can. That same cosineSimilarity function that we used to compare a post's embedding to an embedded search term can also be used to compare one post to another. If we do that for all the posts in our blog's archive, then we compare the similarities to find the N most similar posts.
I've also added some GPT-powered sugar on top of the standard "related posts" concept by getting GPT4 to tell us why the two posts are similar. This lets me flesh out the related-posts section with useful information that will hopefully entice readers into exploring more articles on my site.
Calculating the related posts
I've written a node script that does this for my blog posts every time I publish a new article. The script works like this:
- It reads all the markdown (
.mdor.mdx) files in my content directory, and extracts the relevant content (i.e. the title, subtitle, and body-copy of the post). - This post content is then sent to the OpenAI embeddings API to generate a single embedding for that whole post.
- I then use the completions API to summarise the content of each post. This will help me in later steps because the API has limits on how much text it can parse at any one time. Sending over two full blog posts' worth of content will mean I quickly hit the limits and can't generate the "why are these posts similar?" text. By creating a shorter summary of each post at this stage, I can then use those summaries in my later prompts.
- For each post, the script then finds the top two most-similar posts based on the cosine similarity of the embedding vectors.
- For each "similar post" the script then compares the posts' summary with the summary of the starting post, and sends these to GPT4 to generate the "why these are similar" text.
- The final step is to write this "similar posts" data back into the frontmatter of the original markdown files.
Because this script just needs the markdown files of my blog posts, it can live outside the normal build pipeline of my site. In fact, it could work just as well with any Static Site Generator - if you've got a folder of markdown files, this script would work just fine.
Gotchas
Seeing the script laid out step-by-step like that makes it all look rather simple, but there were a few obstacles to overcome that turned an hour's POC into several days' worth of development effort.
Gotcha #1: API Rate limits
It turns out that you can't just spam the OpenAI API with hundreds of requests all at once, so I had to add pauses in my script to account for this. When in "dev mode" the script will stop any wait for user input ("press y to continue") after every API call, but also has a simpler mode for automatically running through all the requests: it just waits for 6 seconds after every API call to before continuing.
Gotcha #2: API token limits
As I noted in step #3, the API also has a "context limit" - a.k.a. how much content can it process at once. This is measured in "tokens" (which roughly works out to a token or two per word in a sentence). For GPT3.5 the token limit is 4,097 tokens, and for GPT4 the limit is 8,192.
Gotcha #3: GPT4 pricing
The OpenAI API is not free to use. Thankfully the embeddings requests are really cheap, and in the process of building and debugging my script I generated literally hundreds of embeddings (using the text-embedding-ada-002 model) and never got my usage above even a single dollar. GPT3 (using the gpt-3.5-turbo model) is a little more expensive, and GPT-4 is even more so!
While the cost of generating the embeddings was negligible, generating the "why are these posts similar" text cost about two and half dollars per run of the complete script. This was for my personal blog which has about ~50 posts, and includes generating the summaries and then using those summaries to generate the final text.
For my own sanity I've spent a lot of time implementing caching to avoid running scripts multiple times for the same content, so future runs (i.e. when new posts are added to my site) will cost a lot less (generally somewhere between a few cents and a dollar).
Gotcha #4: Prompt tweaking
Again, the embeddings side of things doesn't require any trickery or shenanigans (it just works!), but generating the GPT summaries and "why are these posts similar" content required a bit of what the hype-merchants call "prompt engineering". In my experience, the GPT models can be a bit enthusiastic when generating text, so it took a little bit of careful prompt phrasing to stop them creating over-the-top SEO-fodder (the kind of stuff that marketers and Google seem to love, but real humans hate).
If you're interested, here's the full prompt I used to generate the "why are these two posts similar" text:
You are an automatic recommendation engine for my technical blog. At the end of each blog post, you recommend other posts that readers may be interested in.
I'll provide the summaries for two blog posts. Can you describe why someone who has just read the first post might be interested in reading the second post?
Here is the first post:
${postSummary}
Here is the second post:
${similarPostSummary}
Here are some additional instructions to help you write the recommendation:
* Focus on the facts included in the post and the author's opinions.
* Start every summary with "This is similar to what you've just read because"
* Limit responses to single sentence.
* Avoid hyperbole (such as "It's an enlightening read" or similar). Just describe the similarities of the post and why it might be interesting to someone who has just read the first post.
There a lot of hand-wavey stuff going on there, but after a lot of experimentation that was the prompt that gave me the most reliable results.
Gotcha #5: Inconsistent output
Annoyingly, even with a super-specific prompt the output from GPT generation is not always consistent. For instance, it sometimes adds quote marks around the final text, and other times it doesn't. Not a huge issue, but something that does need to be accounted for at the code level.
Gotcha #6: Hallucination
Even when mostly relying on hallucination-less embeddings, and even when being super-explicit with my prompts and providing all the relevant content in the API requests, even then, hallucination is a bit of a problem. When generating the summaries it can be subtly wrong about the content of the post it's summarising, and when describing why two summaries are similar it occasionally went off-piste and misunderstood the meaning of a post.
After a lot of prompt-tweaking and experimentation I've ended up with a script that I'm happy with for this specific application, but it does highlight the general problem with hallucination. Now I've spent more time working with these LLMs it's really apparent to me that the hallucinations are the biggest obstacle to doing "useful work" with LLM content generation.
Gotcha #7: Post deletion (requires recalculating similarities)
Predictably (although I didn't predict it when writing the first iteration of the script!), when a post is deleted or changed you need to re-generate (or at least check) all the similar posts for all of the posts. Easy enough to handle when the content has changed, but deleting a markdown file did result in my script exploding in annoying and hard to debug ways. Got it sorted in the end, but it was enough of a headache to include on this list!
Gotcha #8: Node memory
This was the biggest bit of uncharted territory for me. Storing all that content in Node's memory meant I eventually hit the memory ceiling! Keeping the post content in memory wasn't an issue, and nor was storing the object that contained the summaries and the similarities. The killer (from Node's perspective) was keeping all that and the embeddings (i.e. a whole load of arrays each with 1536 floating points) and not being smart about how many times I map and reduce the data and trying to write them to a file. Probably a problem I would have avoided entirely if I had a CS degree and knew more about what "Big O" meant, but I got there in the end.
Script optimisation
In the end I did quite a lot of "optimisation" work to get the script to a place where I could rely on it for all the scenarios in my blog workflow (calculating the initial "related posts" for a folder of markdown files, regenerating when new posts are added, handling changes to old post content, and removing and renaming posts).
Caching
To avoid making repeated calls to the (expensive) API for content I'd already generated, I saved the results to a local cache file. If an embedding already existed in my cache, then I could skip fetching that API response a second time. This saved on both execution time and money spent. To invalidate the cache, I generated a sha256 hash from the post's content (being sure to hash just the posts' title and content and not the frontmatter, as the script saved it's results in the posts' frontmatter and would therefore instantly invalidate the cache).
Separate cache storage for embeddings
The embedding arrays, being as long as they are, were a big memory-management concern. In the end, I cached those separately to the rest of the data and just saved a unique key for each embedding in the main cache. That meant that only the embeddings that I actually needed would be loaded into memory.
Regenerate only when content has actually changed
With the cache/hash pattern in place, the script was able to tell if a post's content had changed since the last time the script had been run. This meant I could skip API calls for any post that hadn't changed, but a subtle "gotcha" was that I still needed to regenerate the related posts for a given post if any of the relations had changed. Thankfully the embedding-based similarity calculation was fast and cheap and could be done without calling any APIs, so I only needed to regenerate the GPT-generated content if the relations had actually changed (I'd re-calculate the relations for every post, but then if the resulting relations were the same for a post, they could be safely skipped).
Ship it!
So with the script complete the only thing left to do now is use the thing! The script is triggered by running the command yarn related, and the output looks like this:
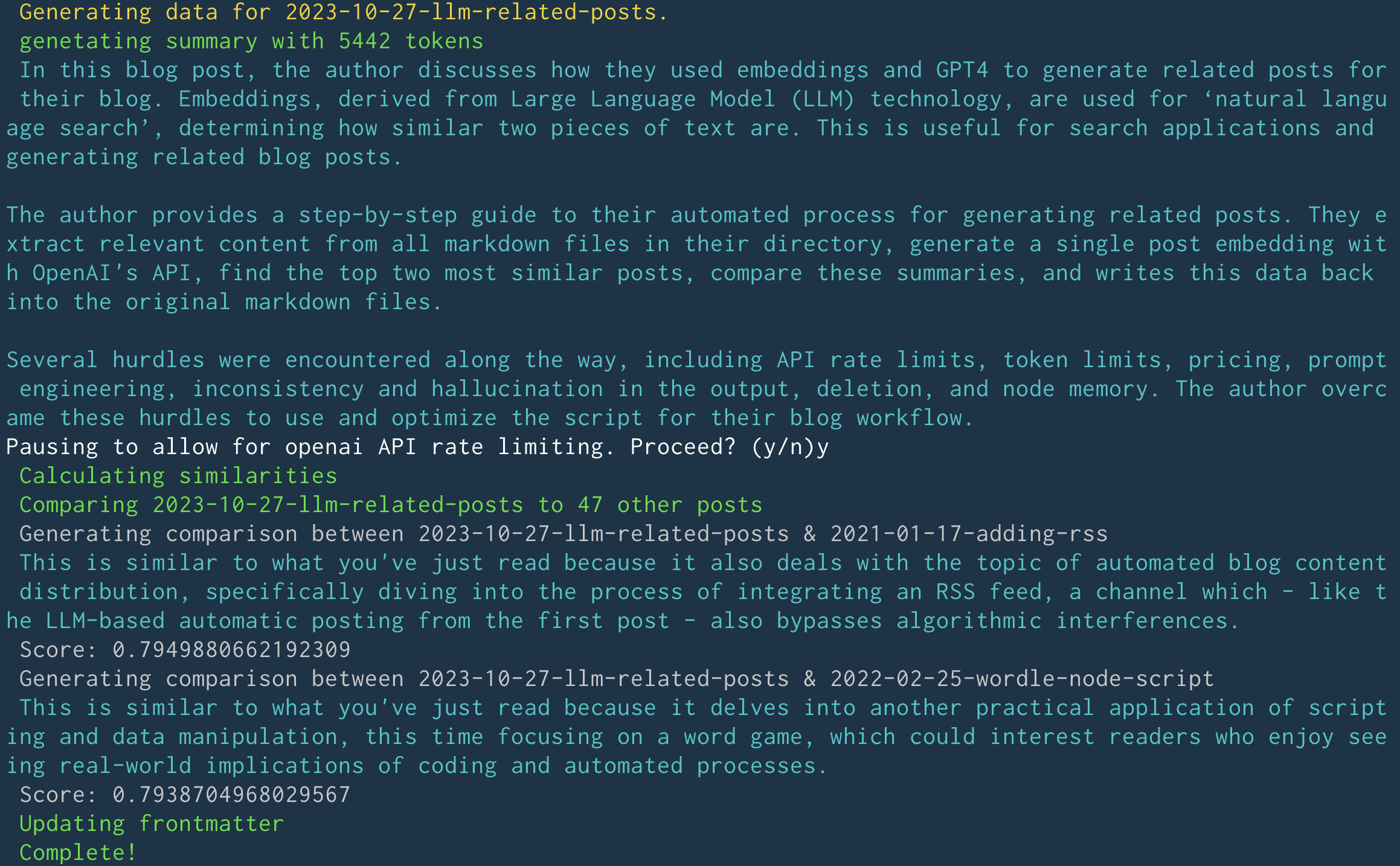
That output is a little verbose, but it's useful for debugging and for seeing what's going on under the hood. The script also updates the frontmatter of the markdown files with the related posts data, so the final result looks like this:
related:
- relativePath: 2021-01-17-adding-rss
permalink: /adding-rss/
date: 2021-01-17
tags:
- articles
categories:
- code
title: RSS in 2021 (yes, it's still a thing)
excerpt: Adding an RSS feed to an Eleventy site is (mostly) easy peasy.
summary:
- This is similar to what you've just read because it also deals with the
topic of automated blog content distribution, specifically diving into
the process of integrating an RSS feed, a channel which - like the
LLM-based automatic posting from the first post - also bypasses
algorithmic interferences.
score: 0.7949880662192309
- relativePath: 2022-02-25-wordle-node-script
permalink: /wordle-node-script/
date: 2022-02-25
tags:
- articles
- featured
categories:
- code
title: Improving my Wordle opening words using simple node scripts
excerpt:
Crafting command-line scripts to calculate the most frequently used
letters in Wordle (and finding an optimal sequence of starting words).
summary:
- This is similar to what you've just read because it delves into another
practical application of scripting and data manipulation, this time
focusing on a word game, which could interest readers who enjoy seeing
real-world implications of coding and automated processes.
score: 0.7938704968029567
That YAML frontmatter gives me enough content to build a nice little template wrapper for the related posts section of my site. And with all that complete, you should be able to view the real-world results of this script at the bottom of this very page. The "related posts" functionality is live on this blog, and I'm pretty happy with the results. I've been using it for a few weeks now and it's been working well.
How much does it cost to run?
For the record, running that script with a single new blog post resulted in four calls to the GPT4 completions API endpoint, which cost roughly thirty cents (prices in USD as that's what OpenAI use in their billing).
Is the script available for anyone to use?
Update: Yes, yes it is. I've opend-sourced the script and published it to NPM. You can find it here: github.com/tomhazledine/related-posts. Currently needs an OpenAI API key to work, but I'm working on a way to hook it up to other LLMs. If you have any questions or suggestions feel free to raise a PR or @ me on Mastodon (I'm @tomhazledine@mastodon.social).
Not yet, but it could be soon. If you're interested in implementing something similar for your own site, I'm not far off packaging the script into something universal that I can open-source on NPM. So if that would be useful to you, then @ me on Mastodon (I'm @tomhazledine@mastodon.social). If more than a couple of people ask me, I'll happilly put in the work to make the script more generic and publish it. It's 90% done already, but as with all software projects I'm anticipating the final 10% of the work will take 90% of the time!
Related posts
If you enjoyed this article, RoboTom 2000™️ (an LLM-powered bot) thinks you might be interested in these related posts:
Mapping LLM embeddings in three dimensions
Visualising LLM embeddings in 3D space using SVG and principle component analysis.
Similarity score: 74% match . RoboTom says:
Improving my Wordle opening words using simple node scripts
Crafting command-line scripts to calculate the most frequently used letters in Wordle (and finding an optimal sequence of starting words).
Similarity score: 72% match . RoboTom says: