Improving my Wordle opening words using simple node scripts
Crafting command-line scripts to calculate the most frequently used letters in Wordle (and finding an optimal sequence of starting words).

Are you just here to see the letter-frequency info? Jump straight to the pretty graphs here. Want to see the full code? View it on GitHub
Let’s be honest, by this point you’re either addicted to Wordle1 or sick to death of hearing about it. And yes, I'm shamelessly using Wordle as click-bait for this post. Having lured you in with the promise of Wordle-insight (which I will deliver!) I'm going to try and get you excited about writing tiny scripts.
Tiny scripts that you run in your terminal can help with, well, pretty much anything involving large amounts of data. They can help you with the stuff that humans are generally bad at but computers are great at. Like analysing the 12,972 words that Wordle uses in its code.
I want to find a sequence of guesses that covers as many of the most common consonants as possible.
My strategy is to hit the most common letters as quickly as possible, but at the same time be able to get through as many guesses as possible without repeating letters. I’m not “solving” Wordle; I just want to optimise my opening sequence of guesses to make playing it more fun.2
The practical considerations of my approach:
- Try to minimise the amount of vowels in the first couple of guesses. Once you get past guess #3 words are harder to form without repeating letters, so keeping some handy word-makers in my pocket is helpful.
- It would be really helpful to know which letters actually are the most common (rather than just relying on my flawed gut-feel).
- I need a "complete" dictionary of words to choose from (a.k.a. my own vocabulary is not good enough).
I can solve all three issues by writing a little bit of code that I'll run on the command-line in my terminal app.
Scripts can be gross and "bad", as long as they work
One joy of tiny scripts is that they're just for me and all I really care about is the output. That means I can use whatever language I like. I spend most of my time writing JavaScript so I'll use Node for my scripts, but you can 100% get the same results with Python or PHP or bash or whatever you like.
It also means that I can play fast and loose with "best practices". Working something out for thousands of items (in this case the Wordle words) is practically impossible by hand, but easy for a script, so even if my code is objectively terrible (with multiple inefficiencies and O(n log n) complexity), the computer can still calculate the result in fractions of a second.
I also don't need to worry about extensibility or re-use. As long as it works for the data-set I'm working with right now, that's fine! I'll just throw this script away when I'm done anyway.
Where does Wordle get its words from?
The source code of Wordle3 contains two arrays of words which I'm calling "winners" and "guesses". winners has 2,315 items and shows all the potential winning words, whereas guesses is longer (10,657) and contains all possible valid guesses.
export const winners = ["cigar", "rebut", "sissy", "humph", "awake", /* etc. */ ],
export const guesses = ["aahed", "aalii", "aargh" /* etc. */];
// Combine the two lists into one array
export const words = [...winners,...guesses];
Which letters are most common?
Working out the frequency of letters is a three-step process. The first step is to count how many times each letter appears in the list of words. Then I need to sort those letters into a useful order (most frequent at the start, least frequent at the end). The third step is to work out the relative frequency of each letter from the raw count.
The initial counting is done by importing our word list4 and flattening it to a single string of letters with words.join(''). We then turn this into an array of letters with a "spread": [...words.join('')]. The we run that array through a reduce() operation to create an object where every letter is a key with a the letter's count as a value.
import { words } from "./dictionary.js";
const letterFrequency = letters =>
letters.reduce((total, letter) => {
total[letter] ? total[letter]++ : (total[letter] = 1);
return total;
}, {});
const allLetters = [...words.join("")];
const unsortedFrequencies = letterFrequency(allLetters);
That letterFrequency() function produces an output that looks like this:
unsortedFrequencies: {
h: 1371,
d: 2060,
l: 2652,
// etc...
}
Sorting is a bit fiddly. Because our unsorted letters are in object-form, we'll need to use Object.keys(frequencies) to allow us to map through the keys and apply a .sort() to them.
const sortFrequencies = frequencies =>
Object.keys(frequencies)
.map(key => ({
letter: key,
count: frequencies[key]
}))
.sort((a, b) => frequencies[b] - frequencies[a]);
const sortedFrequencies = sortFrequencies(unsortedFrequencies);
The third step is to calculate the percentage that each letter occurs in the full list of letters. I'm aiming for accuracy to two decimal places here, hence the * 100 and / 100 dance I need to do to get the rounding to work.
const calculatePercentages = (totalCount, frequencies) =>
frequencies.map(frequency => {
const percentage =
Math.round((frequency.count / totalCount) * 100) / 100;
return { ...frequency, percentage };
});
const percentages = calculatePercentages(allLetters.length, sortedFrequencies);
Letter frequency results
So what does this little script discover? I've saved it in a file called frequencies.js, so to run it I open my terminal, cd to the directory that contains the script, and run:
node frequencies
For my real version I "wasted" some time building a little function to print the results as a graph directly into my terminal (see the screenshot), but for this post I've prettied-up the results a little more.
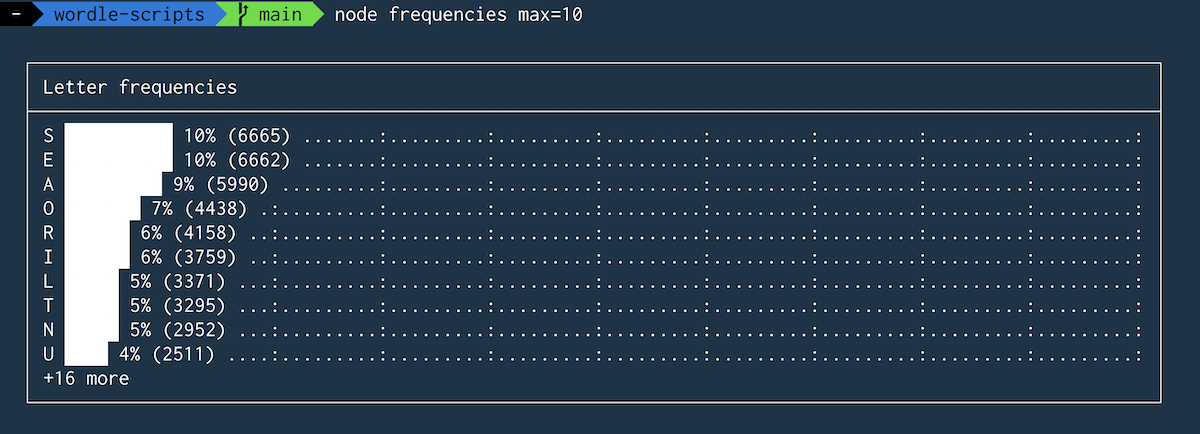
My first run of the script found the most common letters in the entire Wordle "dictionary". Unsurprisingly the vowels all ranked pretty high, but the most commonly occurring letter was S.
For my second run of the script, I filtered out the vowels. This doesn't change the values for any of the letters, but lets me focus on the letters that I think might be more "valuable" when choosing Wordle guesses.
For completeness, and to assuage my curiosity, I also ran the script against just the "winning" words. This one is potentially a "spoiler" and some could call it cheating, so feel free to skip these results if you like. It was interesting, however, to see how the frequencies changed for this reduced set of words!
Finding the best sequence of words
The next script I need will be my word finder, which I'll create in a file called wordfinder.js. To apply the letter-frequency information from the previous step, I'll need a script that can do two things:
- Find all the words from the list that contain a given set of letters (a.k.a. find all words in the list that contain "a", "b", and "c")
- Find all the words that do not include any of the letters in a given set (a.k.a. find me all the five-letter words that do not contain: "abcdefghijk")
// Find words that contain *all* input letters.
const inclusiveMatches = (input, words) => {
const letters = [...input];
const matches = words.filter(word => {
const hits = letters
.map(letter => word.includes(letter))
.filter(hit => hit);
return hits.length == letters.length;
});
return matches;
};
// Find words that do *not* contain any of the input letters.
const exclusiveMatches = (input, words) => {
const alphabet = "abcdefghijklmnopqrstuvwxyz";
const allowedLetters = [...input].reduce(
(a, l) => a.replace(l, ""),
alphabet
);
const match = new RegExp(`^[${allowedLetters}]+$`);
const matches = words.filter(word => match.test(word));
return matches;
};
I could just input the full dictionary from the last script, but there are a couple of other steps I can add to make my search more focused.
One of my objectives is to maximise the amount of the alphabet I cover with my opening Wordle guesses, so I know straight away that I'm not interested in words with repeated letters. A word where every letter is different is known as an "isogram", so with a little regEx magic we can filter out any isograms from our list.
const isIsogram = string => !/(.).*\1/.test(string);
const noRepeatedLetters = words.filter(isIsogram);
Once we have our list of words that match our criteria (words that contain all the MUST_HAVE_LETTERS but none of the MUST_NOT_HAVE_LETTERS), I would find it really useful to sort them by the amount of vowels. Particularly when selecting our first or second Wordle guess, there could be a lot of options (we're dealing with a word-list with >12k entries, after all!). One of my heuristics is that I want my early guesses to include as few vowels as possible in order to maximise the word options on the later guesses.
Sorting by vowel-count is a two step process. I'll need a function to count the number of vowels in a given word, and I'll need a function to sort the words by that count.
const countVowels = (word, vowels = "aeiou") => {
const letters = [...word.toLowerCase()];
const justVowels = letters.filter(char => vowels.indexOf(char) > -1);
return justVowels.length;
};
const orderByVowels = words =>
words
.map(word => ({ word, vowelCount: countVowels(word) }))
.sort((a, b) => (a.vowelCount > b.vowelCount ? -1 : 1))
.map(object => object.word)
.reverse();
Putting it all together
Assuming we've imported the word list and the aforementioned functions, the final flow of the script looks like this:
const onlyIsograms = words.filter(isIsogram);
const set = inclusiveMatches(MUST_HAVE_LETTERS, onlyIsograms);
const subset = exclusiveMatches(MUST_NOT_HAVE_LETTERS, set);
const sorted = orderByVowels(subset);
sorted.map(word => console.log(word));
The only missing ingredients are the MUST_HAVE_LETTERS and MUST_NOT_HAVE_LETTERS variables.
The script could probably be automated to loop through all possible sequences of words and populate these values dynamically, but that's a bit more effort than I'm willing to expend. And besides, this is the stage that requires (in my mind, at least) some external judgement. I want to be able to pick Wordle guesses that feel right (otherwise I'll end up playing "yokul", "speug", or "phpht" - which definitely feel like cheat words even though they are genuine words from the Wordle allowed-list!).
I can get the best of both worlds by adding support for arguments into my script. If I can run node wordfinder include=abc exclude=xyz, for example, then I can quickly iterate over the options I like the look of manually. "Job done", in my opinion!
Adding arguments to a node script
Adding support for arguments in my script involves setting up a config object with my default values, and then looping through the process.argv array (process is a variable that is built into Node and argv is a handy property which makes all the arguments available). For each argument, I'll split by "=" to give me a key and value for each one. So running node myscript foo=one bar=two will give me key/values of foo/one and bar/two. If I include arguments that match the keys of my config options (in this case, inc and exc) then I can overwrite those values, and for the rest of my script config.inc will equal the value I passed into inc=abc.
const config = {
inc: "",
exc: "",
max: 10
};
process.argv.map(arg => {
const argParts = arg.split("=");
const key = argParts[0];
const value = argParts[1];
config[key] = value;
});
Do it!
Finally, after all this work, I can actually begin my search for a suitable sequence of opening guesses for Wordle!
The node frequencies script told me that the most frequently occurring consonants in the Wordle dictionary were S R L T N. To see if (by some miracle) there's a valid five letter word comprised of those exact five letters, I can run my wordfinder script.
node wordfinder inc=srltn
Unsurprisingly, there's no word that matches that criterion 😢. But ditching the n returns three words: "rotls", "slart", and "tirls". Hmmm, not exactly the "feels-right" words I was hoping for. But given that I've already ruled out vowels from my must-have letters on the basis that they're more useful later on, surely s is just as handy a letter to have up my sleeve late-game. Knocking that off the list opens up the options further.
Here are the opening options I experimented with:
| Must-haves | Result count | Result words |
|---|---|---|
| srltn | 0 | |
| srlt | 3 | rotls, slart, tirls |
| rltnd | 0 | |
| rltn | 1 | larnt |
| rltd | 1 | trild |
| rlnd | 0 | |
| rtnd | 3 | trend, drant, drent |
Of these, only trend really feels right to me, so my next step is to run the script again to find my options for the second guess. This time I'll include the exc argument to exclude the letters from my chosen first guess.
node wordfinder inc=lycph exc=trend

| Must-haves | Result count | Result words |
|---|---|---|
| lycpm | 0 | |
| lycph | 0 | |
| lycp | 0 | |
| lyc | 13 | xylic, hylic, cymol, cylix, colby, cloys, clays, calyx, calmy, acyls, scaly, lucky, coaly |
| lypm | 6 | lymph, plumy, palmy, lumpy, imply, amply |
I can then repeat the process, picking new target letters for the inc argument and adding the previous word to the exc argument. This is, in itself, a fun little word game that I've now created for myself, and my little node scripts are what have made it possible.
I've uploaded the complete version of these scripts to GitHub, so you can download them and play with them yourself (and tweak them, if you like). What words did you end up choosing as your opening Wordle guesses? Be sure to tell me about them on Twitter!
Takeaways
If you've made it this far, then hopefully you'll feel empowered to write some fun little scripts to help you out with day-to-day problems. Scripts like this one can save you loads of time (and can actually be used for useful things and not just silly word games). The idea of writing and running my own helper scripts used to feel daunting to me, but knowing they can be written in whichever language I fancy and that there are no stakes whatsoever makes it all seem more accessible.
So next time you're faced with a repetitive task that might take you hours to complete by hand, why not burn a few days writing a script to automate it instead...
- If you’re looking for the most mathematically optimal programatic solution, I’d strongly recommend Three Blue One Brown’s excellent video about solving Wordle using information theory.↩
- I'm not very good at Wordle, but have never "failed" yet. Fewer guesses would be great but my main aim is coverage. I enjoy "clearing" the keyboard - that's the part of Wordle that I find most therapeutic. Getting three or more correct letters in the opening guess is actually quite stressful - the pressure's then on to get a good score!↩
- Wordle is blissfully open source in the best tradition of the web. You can open a web inspector, and the all the code is right there for you to see. And for those of you wondering if anything changed when the NYT took over, the only difference to the word list was that they removed a couple of tricky words.↩
- Here I've used ESM syntax and exported and imported using
exportandimport, but that required setting up apackage.jsonin my script's directory and declaring the script to be a module with"type": "module". You can save this hassle by using the CJSmodule.exports = words;andconst { words } = require('./dictionary.js')pattern, but I think that's ugly. Confused?↩
Related posts
If you enjoyed this article, RoboTom 2000™️ (an LLM-powered bot) thinks you might be interested in these related posts:
TomBot2000: automatically finding related posts using LLMs
How I used LLM embeddings to find related posts for my statically-generated blog and then used GPT4 to explain why they're similar.
Similarity score: 72% match . RoboTom says:
Mapping LLM embeddings in three dimensions
Visualising LLM embeddings in 3D space using SVG and principle component analysis.
Similarity score: 63% match . RoboTom says: